Are Enterprises ready for the Data-centric AI movement?
Enterprises have reached a point of diminishing returns with Model-centric AI. The way forward is to create Data-centric production AI with high-quality, bias-free labeled data.
The present state of AI systems
Today, calling an enterprise AI-driven isn’t extraordinary — digital businesses across industries have incorporated AI to some extent, rendering it commonplace. However, the majority of AI applications are model-centric, meaning the focus is on the model architecture, its fine-tuning, efficiency, etc. In such ready-to-use algorithms, data is often a constant while the model goes through different iterations as requirements demand.
In itself, model-centric AI has no inherent disadvantages. And if it wasn’t for the data proliferation in recent years, maybe model-centric AI wouldn’t be deemed obsolete yet. Needless to say, enterprises have become data-rich but label-poor to a point where model-centric AI is increasingly becoming a liability. The algorithmic performance in such models no longer results in higher returns and positive business outcomes.
Towards Data centricity
The shortcomings of a model-centric approach find a solution in data centricity, where the architecture is predominantly built around training data quality. This approach posits data quality — not modeling — as the means to achieve accurate real-world outcomes. Instead of just feeding excessive data into the networks, emphasis is laid on contextualization beforehand. According to McKinsey’s findings, AI high performers had consistently trained and tested data as a common attribute, which also saw them rake in comparatively higher financial returns.
Labeled data is crucial to data centricity
This begs the question: How does one go about data-centric AI? For starters, data centricity is a shift in focus from data quantity to quality. However, high-quality, bias-free, clean data is not easily achievable amid the proliferation. It is to this end that data labeling is increasingly finding itself among enterprises’ AI strategies.
Labeled data is the foundation of a data-centric AI. However, labeling as a discipline requires reassessment in light of the surge in data because, as one study found out, over 80% of an AI project's time is spent on collating, organizing, and labeling data. This is primarily due to obsolete labeling mechanisms and manual processes.
Data labeling as the pivot
Among digital-first enterprises, there is a general consensus that inefficiencies in the procurement of labeled data are hindering greater AI adoption. These inefficiencies arise from silos between ML Ops platforms and labeled data pipelines. In addition, error-prone manual processes and inconsistencies can impact data quality, subsequently leading to sub-optimal results. So, streamlining procurement is the primary determinant of the efficacy of data-centric AI.
Inefficient procurement hindering AI adoption
If the sourcing is efficient, it is possible for enterprises to maximize the output from deep-learning models and minimize their time-to-market and customers’ time-to-value. Following are the important data-labeling considerations for establishing an actionable data-centric AI.
The more data, the merrier
Non-linear algorithms tend to exhibit low bias and high variance, which can lead to overfitting. While quality takes precedence in data centricity, it also requires considerable quantities to solve the variance issue. This bias-variance trade-off is such that actions taken to lower one aspect will lead to an increase in the other. So, while high variance requires an increase in training data, one must ensure that the collected data is complete and contextualized.
Large volumes of complete and contextualized data to solve the variance issue
As the model is inundated with more data, it will end up leaving the noisy inputs and focus more on the general pattern. However, unlike in the model-centric approach, continuous data collection is critical in data-centric AI.
Ensuring Consistency
An Aristotle quote goes: “You are what you repeatedly do. Excellence, then, is not an act but a habit.” Millennia later, the quote about consistency continues to hold relevance. Accordingly, consistency is also crucial in data-centric AI. A steady supply of labeled data with pertinent annotation guidelines can enable effective evaluation and review processes. The accuracy and consistency in annotation guidelines have a direct bearing on data retrieval and evaluation in different iterations and permutations.
Quality takes precedence
As mentioned earlier, data centricity is predicated not on the quantity of data but on its quality. So, it is safe to say that a well-labeled, small dataset leads to more accurate real-world outcomes than a large, poorly labeled dataset. Additionally, models that are trained on noise-free datasets are prone to cascading when deployed in “noisy” real-world projects. So, the success hinges on periodic iterative cycles aimed at improving data quality. The use of multiple labelers during iterations contributes to data accuracy and corresponding outcomes.
Centralized procurement of Labeled Data
As complexities grow in AI models, the need for higher volumes of labeled data increases. Concurrently, the procured data must be of good quality and capable of generating accurate desired results. This priority discounts the use of publicly available datasets, which tend to be of questionable origins and poor quality — hence unfit for enterprises’ requirements in an increasingly challenging and competitive operating environment.

Centralize procurement for seamless integration
For argument’s sake, let’s consider the procured data is of high quality — what next? If the labeled data is siloed, and if there is no seamless integration between ML Ops platforms and data pipelines, the quality of data will not be as consequential as it can be. This is perhaps why the centralization of procurement is finding takers across the AI value chain.
Centralization essentially bridges the silos between teams, creating data synchronization and streamlining procurement. In data-centric AI, the algorithms also allow domain-specific labeling teams to customize as per use cases. Such possibilities complement the requirements in fast-moving sectors like e-commerce, where AI models require vast amounts of labeled data and the outcomes, such as hyper-personalization, have low margins of error.
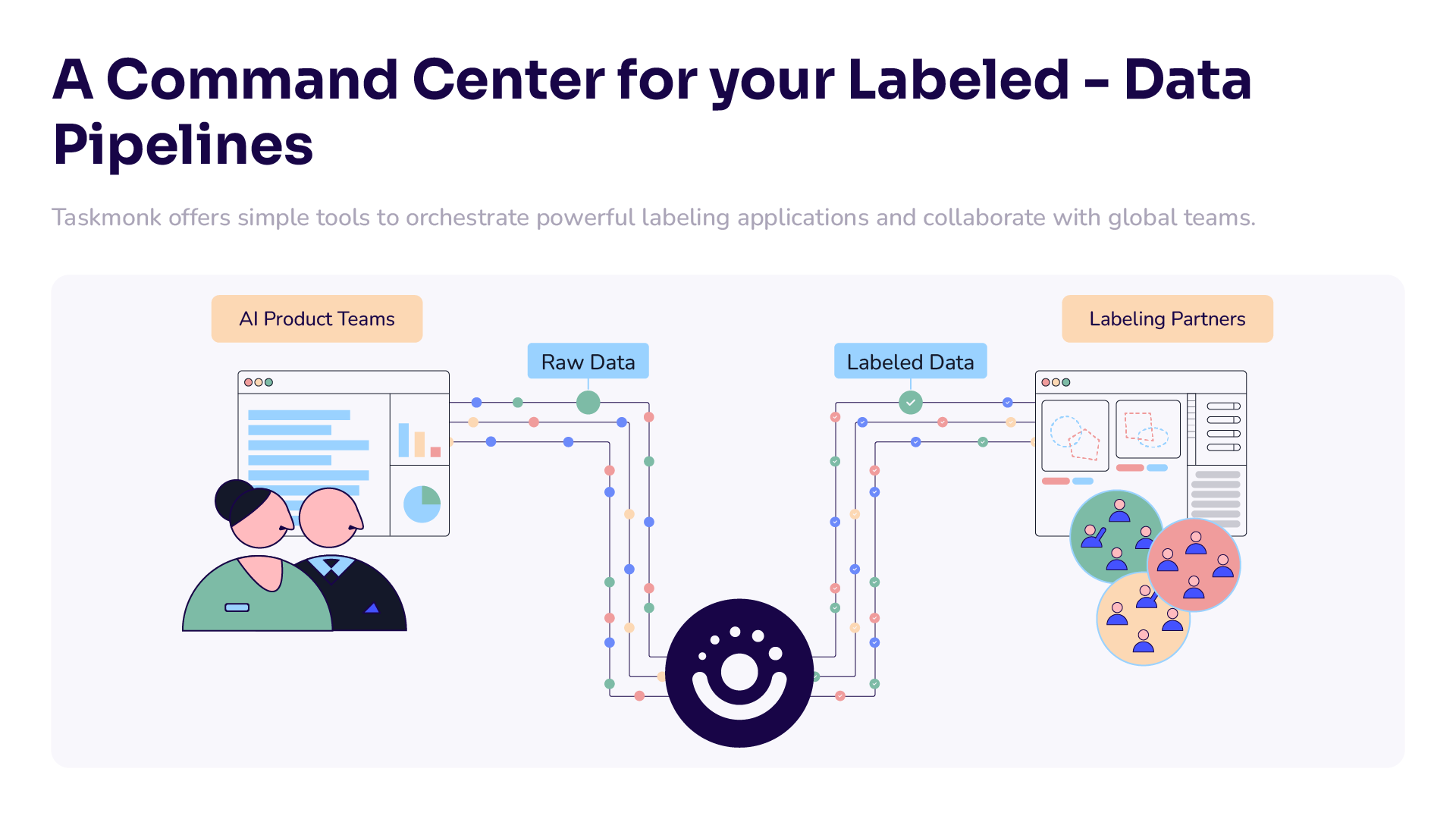
As a centralized procurement platform with a specialty in use-case-specific labeling, Taskmonk is well equipped to cater to the modern-day requirements of competitive sectors like eCommerce.
The Taskmonk Advantage
At Taskmonk, we power data labeling operations for enterprises enabling them to create differentiated data-centric AI at scale.
Create data-centric AI at scale
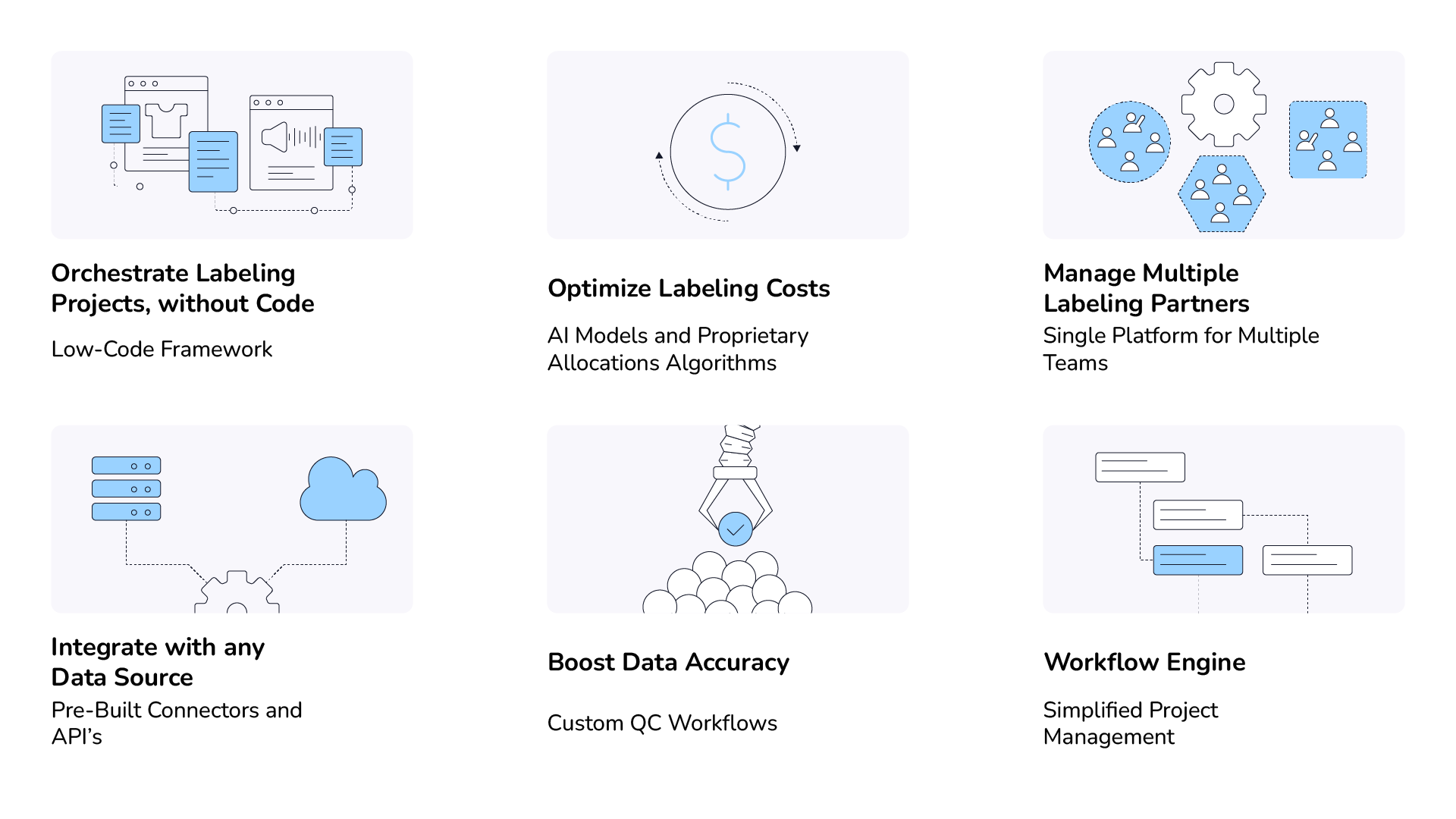
Using Taskmonk, AI teams can manage multiple labeling partners on a single platform and optimize labeling costs using our proprietary allocation algorithms and AI models. Taskmonk’s purpose-built no code framework also allows AI teams to create customized labeling solutions and QC workflows across data types and labeling processes.