

How AI-powered Data Labeling Platform Can Streamline Your Data Annotation Process
Data is the lifeblood of modern businesses, and it is the foundation on which AI-powered technologies are built. But when it comes to raw data it is just that - raw. It needs to be carefully labeled and structured to be of any use.
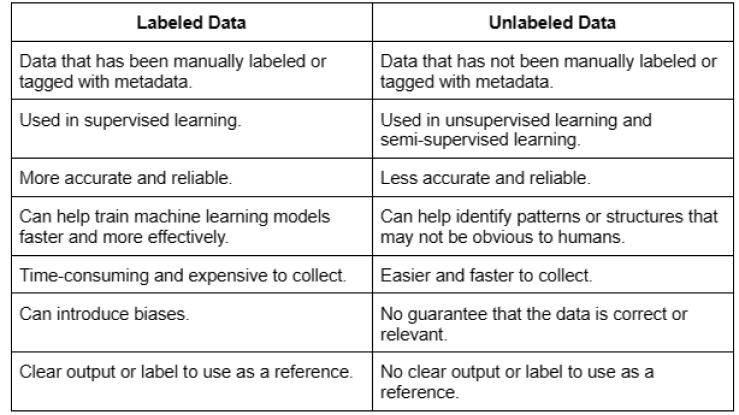
That's where data labeling comes in. Labeled data provides several benefits, including improving the accuracy of machine learning algorithms, enhancing customer experiences, and enabling better decision-making. It also helps to identify patterns and trends in large datasets, leading to insights that can drive business growth. And one way to achieve high-quality labeled data, is by using a reliable data labeling platform.
So, if you're ready to take your data to the next level, here is your guide to accelerate your data labeling process using a versatile and collaborative data labeling platform.
"Data is the new oil" - Clive Humby
What is Data labeling?
Data labeling is the art of transforming chaos into clarity. Also known as data annotation, it is a crucial step in the preprocessing phase of machine learning (ML) model development. In simple terms, data labeling is a process of organizing and structuring data so that it becomes useful and informative.
Data labeling is the process of adding tags or labels to data so that machines can understand and learn from it. It's like putting name tags on things so that a computer can recognize what they are.
For example, imagine a computer trying to identify different objects in a picture. Without labels, the computer would not know which part of the image represents a dog, a tree, or a car. By labeling the image, we help the computer "see" the image in the same way that we do, which allows it to perform tasks such as image recognition, speech recognition, and natural language processing.
This often involves sorting through massive amounts of unstructured data to identify key features and attributes, which can then be labeled and categorized for use in machine learning models and other AI applications.
Common types of Data Labeling
Image classification: Assigning labels to images to categorize them into different classes, such as animals, vehicles, or landscapes. This type of data labeling is commonly used in various applications such as image recognition for autonomous vehicles, medical imaging for disease diagnosis, and e-commerce for product recognition.
Text classification: Text classification is widely used in natural language processing applications such as sentiment analysis, spam filtering, topic classification, and customer support chatbots.
Named entity recognition: Identifying and labeling entities in text data, such as people, organizations, locations, or products. Named entity recognition is commonly used in information extraction tasks such as news article analysis, legal document analysis, and chatbots.
Audio transcription: Transcribing spoken words into text and labeling them with appropriate tags, such as speaker identification or sentiment analysis. Audio transcription is used in various applications such as call center analytics, speech recognition, and language learning.
Semantic segmentation: Assigning labels to every pixel in an image to identify and differentiate different objects within the image. Semantic segmentation is commonly used in autonomous vehicles, medical imaging, and robotics for object recognition and tracking.
Common Approaches of Data Labeling
Data Labeling is a critical step in developing high-performance machine learning (ML) models. Although it may seem simple at first glance, implementing it can be a daunting task. Therefore, companies must consider various factors and methods to determine the best approach to labeling.
Each data labeling method has its own advantages and disadvantages, and a detailed assessment of task complexity, project size, scope, and duration are essential. The following are some ways to label data:
Internal labeling involves using in-house data science experts for better tracking, accuracy, and quality.
Pros:
- Greater accuracy.
- Better tracking.
- Improved quality control.
Cons:
- Time-consuming.
- Requires extensive resources.
Synthetic labeling generates new project data from pre-existing datasets, enhancing data quality and time efficiency.
Pros:
- Enhances data quality.
- Requires extensive resources.
Cons:
- Requires extensive computing power, which can increase pricing.
- May not be suitable for all types of data.
Programmatic labeling automates the data labeling process using scripts to reduce time consumption and the need for human annotation. Although this method is efficient, the possibility of technical problems requires human-in-the-loop (HITL) to remain part of the quality assurance process.
Pros:
- Highly efficient
- Cost-effective
Cons:
- Technical problems may arise.
- Quality assurance may still require human annotators.
Outsourcing can be an optimal choice for high-level temporary projects. Hiring managed data labeling teams provides pre-vetted staff and pre-built data labeling tools.
Pros:
- Saves time and money.
- Managed data labeling teams can provide pre-vetted staff and pre-built data labeling tools.
Cons:
- Developing and managing a freelance-oriented workflow can be time-consuming.
- Worker quality and project management may vary across outsourcing platforms.
Crowdsourcing is a quicker and more cost-effective approach due to its micro-tasking capability and web-based distribution. However, worker quality, QA, and project management vary across crowdsourcing platforms.
Pros:
- Quicker and more cost-effective due to micro-tasking capability and web-based distribution.
- Beneficial for specific types of data labeling tasks, such as image classification.
Cons:
- Worker quality, QA, and project management vary across crowdsourcing platforms.
- May not be suitable for all types of data.
ReCAPTCHA is a well-known example of how crowdsourcing can be used for data labeling using bot control, and simultaneously enhancing image data annotation. By leveraging the results of other users, the program could verify itself and generate a comprehensive database of image labels.
Companies must consider various factors and methods to determine the best approach to labeling, and a detailed assessment of task complexity, project size, scope, and duration is essential. By choosing the right labeling method, companies can ensure high-quality results and improve their ML models' accuracy and efficiency.
Challenges in Data Labeling
Challenge #1: Workforce Management
Managing a massive workforce to label tons of unstructured data is like herding cats. And, it's not just about quantity, quality matters too. Balancing training, management, and expanding the team is a tricky act.
Challenge #2: Consistent Data Quality
Data quality is crucial, but it's not easy to achieve. Inconsistent data quality in data labeling arises due to human error and different interpretations of the same data. As the volume of data to be labeled increases, it becomes more difficult to maintain consistent quality over time. This issue is particularly relevant in fields such as healthcare, finance, and marketing where accurate and reliable data is essential for decision-making processes.
Challenge # 3: Data Sources
Managing data from different sources can be a challenge in data labeling. Data can come in various formats, such as text, audio, images, and video, and may require different types of annotations. For example, text data may require sentiment analysis or named entity recognition, while image data may require object detection or semantic segmentation.
Furthermore, data can come from multiple sources, such as social media, e-commerce websites, or customer support logs, each with its own unique characteristics and labeling requirements. Labeling this data manually can be time-consuming and error-prone, leading to inconsistencies and inaccuracies in the labeled data.
Challenge #4: Financial Cost
Pricing for data labeling is all over the place. Companies are struggling to budget correctly without established metrics. Outsourcing can be expensive, and in-house teams need lots of training and time to become experts. As data quantity grows, so do the prices.
Challenge #5: Data Privacy
Data privacy laws are being introduced at a rapid pace. Companies need to comply with regulations when labeling unstructured data that includes personal information like faces and license plates. Data security is essential, and companies need to prevent unauthorized access to data.
Challenge #6: Smarter Tools for Scaling
As companies scale up their data labeling operations, they need smarter tools for labeling automation and intelligent labeling. But, these tools can't replace the human expertise required for subjective labeling tasks.
How to Overcome the Challenges in Data Labeling with the Help of a Data Labeling Platform
Data labeling is a crucial component of ML, as it involves adding metadata/annotations to raw data in order to make it more meaningful and useful for training machine learning algorithms. However, labeling large volumes of data can be a time-consuming and resource-intensive task, often requiring significant manual effort and attention to detail.
A data labeling platform can be an effective solution to overcome the overall challenges in data labeling.
What is a Data Labeling Platform?
A Data Labeling platform (like Taskmonk) provides an environment where human annotators can manually label or tag the data according to specific criteria, such as image classification or sentiment analysis. It can function as a command center for your labeled data pipelines. You can use simple yet effective tools to manage powerful labeling applications and collaborate with teams across the globe.
The global data annotation tools market is expanding rapidly, with a projected CAGR of 26.5% from 2023 to 2030. According to grandviewresearch.com
Why do companies need data labeling platform?
Data labeling can be a difficult and time-consuming process for companies, which is why many are turning to data labeling platforms to streamline the process and improve the quality and accuracy of their labeled data. Here are some of the reasons companies need data labeling platforms.
- Time-consuming and labor-intensive manual labeling: Companies may have to rely on manual labeling methods, which can be time-consuming and labor-intensive, especially for large data sets.
- Limited scalability: Manual labeling methods can be difficult to scale as data volumes grow, leading to delays and bottlenecks in the labeling process.
- Inconsistent labeling standards: Without a standardized labeling process in place, companies may have inconsistent labeling standards across different projects or even within the same project, which can lead to inaccuracies and confusion.
- Undue burden on internal resources: Data labeling requires significant time and effort from staff, particularly when dealing with large datasets. Companies may not have the necessary resources to devote to this task, and attempting to label data in-house can divert attention from other important business activities.
- Lack of internal expertise: Accurately labeling data requires knowledge and expertise in the relevant domain, as well as an understanding of labeling best practices and standards. Companies that do not have internal expertise in data labeling may struggle to label data accurately, leading to inaccuracies and inconsistencies in their datasets.
Benefits of using a Data Labeling Platform
Scalability: As data volumes continue to grow, labeling large amounts of data can become a significant bottleneck. By offering a range of solutions that support scalability and AI maturity, we ensure that our platform can meet the complex and evolving data labeling needs of organizations of all sizes and levels of advancement. We offer flexible pricing options to accommodate both small and large-scale projects, making it easy for clients to scale their labeling efforts as needed.
Quality Control: Labeling errors can have a significant impact on the accuracy of machine learning models, so it's critical to ensure that annotated data is accurate and reliable. Our platform provides built-in quality control mechanisms to verify the accuracy of labeled data through maker checker, maker editor and golden set models. This ensures that the annotated data meets the highest standards of accuracy and reliability. This helps clients to have confidence in their labeled data and the machine learning models they train on it.
Customization: Taskmonk offers a range of powerful customization options to meet the specific needs of our clients. With no-code customization, clients can easily modify their labeling workflows without the need for programming skills. Workflow logics enable clients to define rules and logic for their labeling workflows, ensuring that data is accurately and consistently labeled. UI customization options allow clients to customize the user interface of our platform to meet their branding and user experience requirements. Finally, our workflow builder allows clients to create unique and tailored labeling workflows to meet their specific use cases.
Collaboration: Collaboration is critical to many data labeling projects, especially those involving large volumes of data or complex labeling requirements. Our platform supports team collaboration, enabling multiple users to work on the same project simultaneously and track the progress of their team members. This helps to ensure that projects are completed efficiently and accurately, while also fostering a sense of teamwork and collaboration among team members.
Why Choose Taskmonk's Data Annotation and Labeling Solutions?
Taskmonk is a unified no-code platform, which can handle various data types on the same platform without the need of coding. It is configurable using a simple drag and drop UI. Our annotation software can be used in a variety of industries, including BPM Processes, Logistics, Finance, Ecomm, Fintech, etc. It can be especially crucial for companies that rely on large volumes of data for their ML and AI applications, as the accuracy and quality of the data directly impact the performance of these models.
Taskmonk is a powerful and efficient data labeling platform that offers a variety of benefits for organizations looking to streamline their data labeling projects. Here are a few reasons why you should consider Taskmonk for your next data labeling project:
- Integration with any data source: We can help you manage data from different sources by providing a centralized platform for labeling and organizing data. Taskmonk can be seamlessly integrated into your current technology stack and data flow procedures, with the use of straightforward APIs that allow for real-time two-way data exchange.
- Cost optimization: With AI models and proprietary allocation algorithms, Taskmonk helps optimize labeling costs by assigning work based on worker expertise. You can reduce your cost per label by up to 26% with Taskmonk.
- Improved data accuracy: Taskmonk offers custom quality control (QC) features that help maintain high accuracy levels through additional checks and verifications on labeled data.
- Multiple labeling partner management: Taskmonk enables easy collaboration and management of labeling projects across. Our no-code task builder allows for easy management of labeling applications, even across teams in different locations, resulting in high-quality data and labeling team optimization.
- Workflow engine: We provide an efficient project management process through its workflow engine, simplifying labeling project management from start to finish. With our platform you can reduce the cycle by up to 3X.
- Pre-coded Connecters for Convenience & Security: By utilizing our prebuilt connectors, you can effortlessly link your Taskmonk data to models supported by AWS, Azure, Alibaba, and Baidu with just a single click.
- Lowered Labeling Average Handling Time (AHT): Our AI enriched labeling tools can lower labeler AHT and improve margins by having a single source of truth for reliable and accurate data.
- End to End Labeling Solution: With Taskmonk, you can streamline your data management process and efficiently manage teams to obtain high-quality labeled data with near-perfect accuracy. This purpose-built platform offers a range of features and tools to ensure that the data labeling process is both efficient and effective, allowing your team to focus on more critical tasks.
Different use cases of Taskmonk Data Labeling Solutions
Whether it's labeling product descriptions or analyzing customer feedback, Taskmonk provides accurate and efficient solutions for businesses to extract insights from their data. Here are some of the different use cases for Taskmonk:
- Text data: Taskmonk offers voice processing and data extraction services. For instance, e-commerce companies can use Taskmonk to extract important product information such as product name, description, features, and prices from product images. This data can then be used to create more accurate and informative product listings, which can help increase sales.
- Audio data: Taskmonk offers sentiment analysis and speech to text services. For example, e-commerce companies can use Taskmonk to analyze customer feedback, reviews, and comments to gain insights on the customer experience. This information can then be used to improve the customer experience and increase customer loyalty.
- Computer vision data: Taskmonk offers pixel annotation and vector annotation services. E-commerce companies can use Taskmonk to annotate images with product information, such as product type, size, and color. This data can then be used to improve search results, which can enhance the user experience and increase sales.
- Geo-spatial data: Taskmonk offers geo-fencing and point of interest services. For example, e-commerce companies can use Taskmonk to geo-fence their delivery areas and mark points of interest such as store locations. This data can then be used to optimize delivery routes and provide customers with accurate delivery estimates.
- Competitive intelligence: Taskmonk can help e-commerce companies gain insights on their competitors' products, pricing, and promotions. This information can then be used to develop more effective marketing strategies and improve pricing competitiveness.
- Product classification: Taskmonk can assist e-commerce companies categorize their products more accurately, making it easier for customers to find what they're looking for. Additionally, with attribute extraction services, Taskmonk can extract important product attributes such as material, size, and color, which can be used to improve product descriptions and search results.
- Search relevance: With Taskmonk e-commerce companies can improve the accuracy of their search results, making it easier for customers to find the products they're looking for. This can result in increased customer satisfaction and sales.
- Sentiment analysis: Taskmonk enables e-commerce companies analyze customer feedback and reviews to gain insights on the customer experience. This information can then be used to improve customer service and product offerings.
- Chatbot training: Taskmonk assists e-commerce companies improve their chatbot's performance by providing accurate and relevant data to train their chatbots. This can result in more efficient customer service and improved customer satisfaction.
- Autonomous checkout for retail: Taskmonk can help retail stores reduce checkout lines and improve customer experience by using computer vision technology to automatically detect and charge customers for their purchases as they leave the store.
- Inventory management and autonomous warehouse management systems: Taskmonk can enable e-commerce companies and retail stores manage their inventory and warehouses more efficiently, reducing stockouts and overstocks, and improving overall supply chain efficiency.
- Face recognition: Taskmonk can help companies identify and track customers, improving security, and personalized customer experiences. This technology can also be used for access control, age verification, and fraud prevention.
- Visual search: Taskmonk's visual services can help e-commerce companies improve customer experience by allowing customers to search for products using images instead of text. This can improve search accuracy and reduce search time, leading to increased sales.
- Shopping analytics and personalized recommendations: Taskmonk can help companies gain insights on customer behavior and preferences, improving the accuracy of personalized recommendations and increasing customer satisfaction.
Conclusion
Click the links below to know more in detail about Taskmonk's solution for:
With an end-to-end data labeling solution, a platform like Taskmonk can help you unlock the full potential of your data, and drive towards greater efficiency, productivity, and profitability.
Whether you're a digital company looking to scale up your data annotation game or a Fortune 500 company, we have the expertise to help you succeed in the rapidly-evolving world of AI. Get in touch with our team to know more about.


