

Powering the World from Unexpected Places - The “Humans” creating smarter AI
Widespread AI adoption coupled with renewed demand for HITL training has created a lucrative opportunity for countries like India to leverage Human Capital.
The rise of AI is starting to influence every aspect of human life. And, as far as businesses are concerned, cognitive technology has already established itself as the next big thing in virtually every industry and sector. While headlines often focus on the outcomes such tech-enabled innovations can produce, one of the behind-the-scenes stories central to this growth relates to the collation of quality training data, which AI leverages.
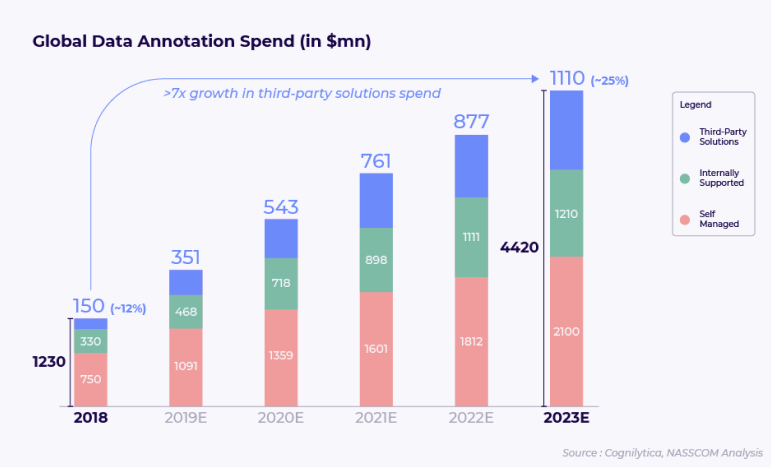
In addition to the compelling business case, based on deriving efficiencies and insights, the global COVID-19 pandemic has further accelerated the rise of AI. Data-driven decision-making has become a vital component for organizations, and this evolution is now irreversible. Along with AI adoption going past a critical threshold, businesses across sectors still find themselves struggling to address the need to train increasingly larger datasets. This is corroborated by the fact that the worldwide outlay on third-party solutions for generating training data is expected to grow 7X between 2018 and 2023.
Data, ML, and the rising need for Automation
A Machine Learning (ML) model is only as good as the quality of the data that enable it. Improving an ML model mainly involves better tuning, increased testing, and optimizing the training data in use. Once an emerging technology, ML is now maturing into a standard capability, with an ever-increasing number of companies deploying models. The focus since this evolution has shifted to fine-tuning a model’s precision and recall by improving how the data is labeled and trained.
The global market valuation for data annotation tools was $494 million in 2020 – somewhat modest compared to other functions. This figure is attributable to the fact that a crowdsourced model of Data Labeling had served businesses reasonably well until recently. “With AI use cases getting increasingly complex, a shift is underway towards a trained human workforce model; to ensure quality and infuse greater clarity into the process.” The CAGR for the global data annotation tools market is now estimated to be an impressive 27.1% between 2021 and 2028.
Currently, this growth is primarily driven by the increasing adoption of image annotation tools in the automotive, retail, and healthcare sectors. Tags and labels enhance the value of data, eliminating the need to rewrite rules in multiple instances, enabling users to manage data definition in one location. Likewise, Big Data and the use of large datasets in AI and Machine Learning applications are fuelling a corresponding growth in the Data Labeling market. Labeling is critical to developing effective AI, and currently, this function is most often outsourced as a specialized but non-core activity for most enterprises. With AI being used to handle more and more use cases and nuanced tasks, the annotation market is at the cusp of massive and rapid expansion.
India, the annotation destination
Given its prior BPO experience, India is now emerging as the world’s top outsourcing destination for Data Labeling. With the pre-requisites in place, the Indian outsourcing market is ready to deliver even higher value than before. Having ticked all the boxes in offering innovation and well-trained talent, building the appropriate infrastructure while retaining its cost advantages, India is looking to add $500 billion to its GDP from Data and AI alone by 2025.
Simply put, the Indian data annotation landscape presents clear advantages for the global market it aims to serve, going beyond the cost-effective workforce, English literacy, and basic computing skills, which drove its BPO boom.
High-speed, affordable internet, and a stable economy compared to other possible candidates in Eastern Europe, Africa, and South-East Asia, make a choice rather obvious. With AI-enabled solutions being implemented across business functions and the use cases becoming increasingly nuanced, efficient Data Labeling services need to deliver on both volume and quality. Bengaluru-based Taskmonk Technology Private Limited addresses the needs of this market through its No-Code Training Data Procurement platform. The platform enables AI-Data Operations Managers to configure Labeling workflows for any use case and data type. Anchoring the continual rise in this segment is an increased focus on supporting infrastructure and, even more critically, the demand for a highly-skilled workforce.
Favoring the trained human workforce model
Having established the crucial role of labeled data in developing ML algorithms and eventually AI, the clear next step for most businesses is determining the workforce to be used to generate the labeled data. Typically, businesses have to choose between crowdsourced and trained workforce models. While each has its advantages, the momentum is slowly but surely shifting in favor of trained workforces operating on an efficient labeling platform. Of course, the variation in requirements – across the scale of the project, budget allocation, security concerns, and future-ready processes – can make the crowdsourced model seem more appropriate for smaller, less nuanced requirement profiles. But, on the whole, a very substantial proportion of AI and ML solutions are now at an intermediate to an advanced stage of maturity, for which the crowdsourced model is sub-optimal.

Using a crowdsourced model to outsource data labeling is also hampered by a lack of transparency. Businesses have little to no insight into the labeling processes employed and are also hampered by limitations in having hands-on control over cost optimization levers. So, while simple use cases that need to factor in consensus can benefit from the crowdsourced model - for instance, when eliminating bias in identifying a product that the average B2C customer prefers – the ongoing enhancements in AI and ML point to more complex priorities in the future. A trained human workforce has a far greater ability to deliver, with regard to more complex tasks and training data for advanced use cases.
As the desired outcomes from Data Labeling and Annotation become more specific, advanced, and complex, a workforce of skilled annotators will increasingly prove to be the more appropriate option compared to crowdsourced platforms.
Increasingly, the choice for a serious AI deployment that addresses complex requirements is between the In-house team model and the Managed Services Model delivered by firms like iMerit, NextWealth, Desicrew, Indivillage, etc.
Why do large Enterprises prefer a use case appropriate model?
Trends are often influenced by the biggest players within a market, and large enterprises are backing optionality, allowing product owners to use multiple labeling vendors based on the data type and stage of maturity in play. Doing this successfully involves ‘knowledge transfer’ between the teams.
Naturally, domain knowledge can prove to be a key factor when the Data Labeling needs are particularly nuanced and the datasets more complex. Such requirements can be extremely specific, from familiarity with the language used in a speech-based dataset to an understanding of the source of data. Nevertheless, while an individual deployment might favor a particular variation, the complexity and sheer amount of raw data needed to train AI increasingly favors a trained workforce model and underscores the need for a centralized labeled-data procurement strategy. Domain knowledge can prove to be a key factor when the Data Labeling needs are particularly nuanced and the datasets more complex.
The limitations of an in-house model are similar to those that drove increased adoption of several other IT functions, from helpdesks and security to data centers. Maintaining a specific team and the associated hardware adds up to a considerable fixed cost.
When it comes to Data Labeling, such inputs are made even more complex due to the constantly evolving quality assurance and control requirements.
In contrast, the outsourced model has the advantages of being able to leverage highly skilled and specialized workforces at a minimal cost, with the capacity to process massive datasets quickly – although clear and well-defined communications are a must.

Delivering Centralized Data Labeling while maximizing flexibility
Taskmonk’s labeler-centric platform allows labeled data procurement to be centralized within teams that the business can choose based on the application. In essence, customers get to select the skillset and experience required to train the data for their AI and ML needs on a project-to-project basis.
With AI proliferating across the enterprise, the use cases often become varied and complex. Curating and providing high-quality labeled data to ensure algorithms are properly trained is a challenge that enterprises face. With the effort taken to label data being linearly proportional to the complexity of the AI use case, most enterprises will often choose to label the complex tasks in – house and outsource the rest to labeling vendors.
Taskmonk has been built to ensure that this synergy between in-house labelers and outsourced vendors works as seamlessly as possible, with provisions made to facilitate seamless transfer of learning.
As the labeling process matures, in-house teams can choose to allocate batches of their choice between vendors, confident in the knowledge that they have a robust QC module at their disposal.
High quality labeled data is the fuel that keeps the AI machine running. The involvement of humans in training ML algorithms for better, more relevant AI cannot be understated and will prove vital in accommodating the myriad of growing AI applications.


